
Help
Index
Introduction
Nowadays the advent of high-throughput sequencing (HTS) technologies is transforming multiple research fields as well as the analysis of the intrinsic heterogeneity of phage libraries. Phage display technology coupled with deep sequencing (Interactome-sequencing) was introduced in 2010 [Di Niro R. 2010] and holds the potential to circumvent the traditional laborious picking and testing of individual phage rescued clones. However, from a bioinformatic point of view the analysis of this kind of data was always performed by adapting tools designed for other purposes, thus not taking into account the noise background typical of interactome-sequencing approach and the heterogeneity of the data.
InteractomeSeq is a web server allowing domainome data analysis from either Eukaryotic and Prokaryotic genomic phage libraries generated and selected by following an interactome-sequencing approach. InteractomeSeq is free available through a user-friendly web interface and allows users to upload raw-sequencing data and easily obtain an accurate characterization of domainome/epitome profiles after setting the parameters required to tune the analysis procedure.
InteractomeSeq web server implements a new analysis pipeline composed of three sequential steps: i) the “Uploading” step allows to upload raw sequencing reads, reference genome sequence and annotations, and checks their syntax correctness; ii) the “Mapping” step trims and discards low quality and short sequencing data, and aligns remaining reads to the reference genome; iii) the “Domain Analysis” step, composed by 4 sub-steps, performs the domains detection and generates a list of portions of genes classified as putative domains/epitopes associated to their annotations. A “Results” page contains all the final and partial results in different visualization type: tabular format, Venn diagram and an embedded genome viewer (jBrowse [Buels R. 2016]) in order to display the tracks of the predicted domains and the relative abundance. A web link, containing a unique 28-characters ID, allows the user to bookmark, visualize the results and re-run some analysis steps within 15 days, if needed.
All the datasets described in the tutorial and deriving from previously published papers are made available [Di Niro R. 2010; Gourlay L.J. 2015; Patrucco L. 2015; Cortini A. 2019]. Moreover, the analysis of new datasets deriving from the generation of Helicobacter pylori (HP) genomic phage library, through the interactome-sequencing approach, and its selection against sera from HP-positive and HP-negative healthy individuals, have been included in the Help/Tutorial section of the web server. These new datasets, also available in Sequence Read Archive, provide a comprehensive analysis of the antibody repertoire related to HP infection and represent an important source of diagnostic information, serving as biomarker to outline an “infection signature”.
The release of this tool is relevant for the scientific and clinical community, because InteractomeSeq will fill an existing gap in the field of large-scale biomarkers profiling, reverse vaccinology, and structural/functional studies, thus contributing essential information for gene annotation or antigen identification.
InteractomeSeq is implemented in AngularJS, a structural framework for dynamic web applications, on the basis of a Python2.7 package available at https://github.com/sinnamone/InteractomeSeq .
InteractomeSeq is available without registration at http://interactomeseq.ba.itb.cnr.it or https://interactomeseq.ba.itb.cnr.it - SSL secure connection.How to start a Project
InteractomeSeq allows the user to use the webtool without registration, by clicking on the button ( ) in the Home page or in the top menu.
An email will be sent with a link to the user with the Project ID. The Project will be stored for 15 days.
The user can resume the analysis, delete or add dataset and download the results.
) in the Home page or in the top menu.
An email will be sent with a link to the user with the Project ID. The Project will be stored for 15 days.
The user can resume the analysis, delete or add dataset and download the results.
If you need to execute and store multiple projects, you can register by email and password. Once you login you will find/manage a list of stored projects.
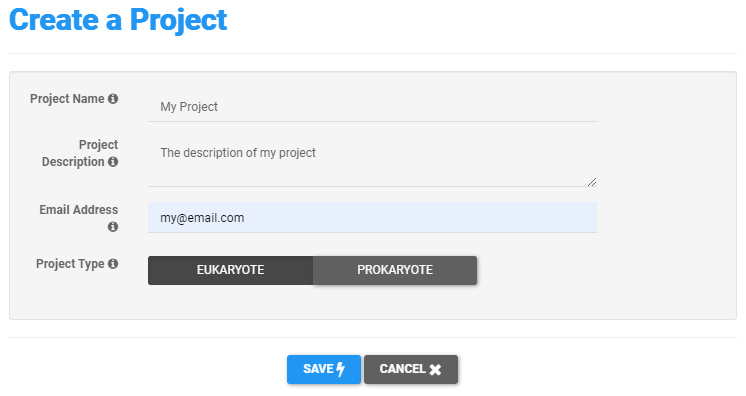
For each project, InteractomeSeq allows the user to select the type of analysis between:
- PROKARYOTE genomic domainome analysis
- EUCARYOTE genomic domainome analysis

Analysis
The core of the InteractomeSeq analysis pipeline are the analysis steps located in the "DOMAIN ANALYSIS" page of a Project. In particular:
- Domain Definition. The output of the domain definition step consists of all soluble domains/epitopes detected flanked by the corresponding protein coding information.
- Domain Enrichment. The output of the domain enrichment step provides the expression of all soluble domains/epitopes detected from the Selection sample statistically tested (edgeR) against Genomic domains/epitopes.
- Domain Subtraction. The output of the domain subtraction step lists the soluble domains/epitopes that result from the subtraction between two differentially enriched Selections.
- Domain Intersection. The output of the domain intersection step represents the unique e common soluble domains/epitopes that result from the intersection of two or three differentially enriched Selections. The results are displayed in a Venn plot.
All the results of the Domain steps could be displayed in tabular format and in an embedded genome viewer (jBrowse) in order to display the predicted domains and the relative abundance.
Combinations of the custom python script together with general bioinformatics tools like Cutadapt,Trimmomatic, Blast and Kallisto compose different InteractomeSeq pipelines adapted to the computational needs of each analysis type. Although three different types of analyses are offered, the aim of the bioinformatic approach remains the characterization of domainome/epitome profiles.
For each project type a detailed user guide on how to run the analysis steps see the following documents:
For a detailed tutorial of step-by-step execution of some examples see Tutorial & Examples section below.
Tutorials & Examples
Descriptions and Executions ( ) of the complete step-by-step analysis for each example projects, including the input dataset files (
) of the complete step-by-step analysis for each example projects, including the input dataset files ( ), are available in the following table:
), are available in the following table:
| Step-by-Step Tutorial |
Project | Organism | Type | Article | Input Files | Executions |
|---|---|---|---|---|---|---|
| Hp 26695 | Helicobacter pylori | Prokaryote | --- | |||
| Rna Binding Protein | Homo sapiens | Eukaryote | Fasolo F, et al. | |||
| RIDome | Homo sapiens | Eukaryote | Di Niro R, et al. |
In the InteractomeSeq home page, the box “Examples” allows users to have a look at the previous examples of InteractomeSeq analysis.
Browser Compatibility
InteractomeSeq, based on AngularJS framework, has been tested with major modern browsers:
| OS | Version | Chrome | Firefox | Microsoft Edge | Safari |
|---|---|---|---|---|---|
| MacOS | Mojave | 71 | 64 | n/a | 12.0 |
| Windows | 10 | 71 | 64 | 42 | n/a |
| Linux | Ubuntu 16.04 | Not Tested | 64 | n/a | n/a |
For a better usage, we recommend users to access InteractomeSeq using Chrome or Firefox from a computer with at least 4G RAM and 1200 x 800 screen resolution. If you encounter an issue with your browser, try updating it to the latest version (Browse Happy ). If you still have problems, contact us: bigstaff@ba.itb.cnr.it